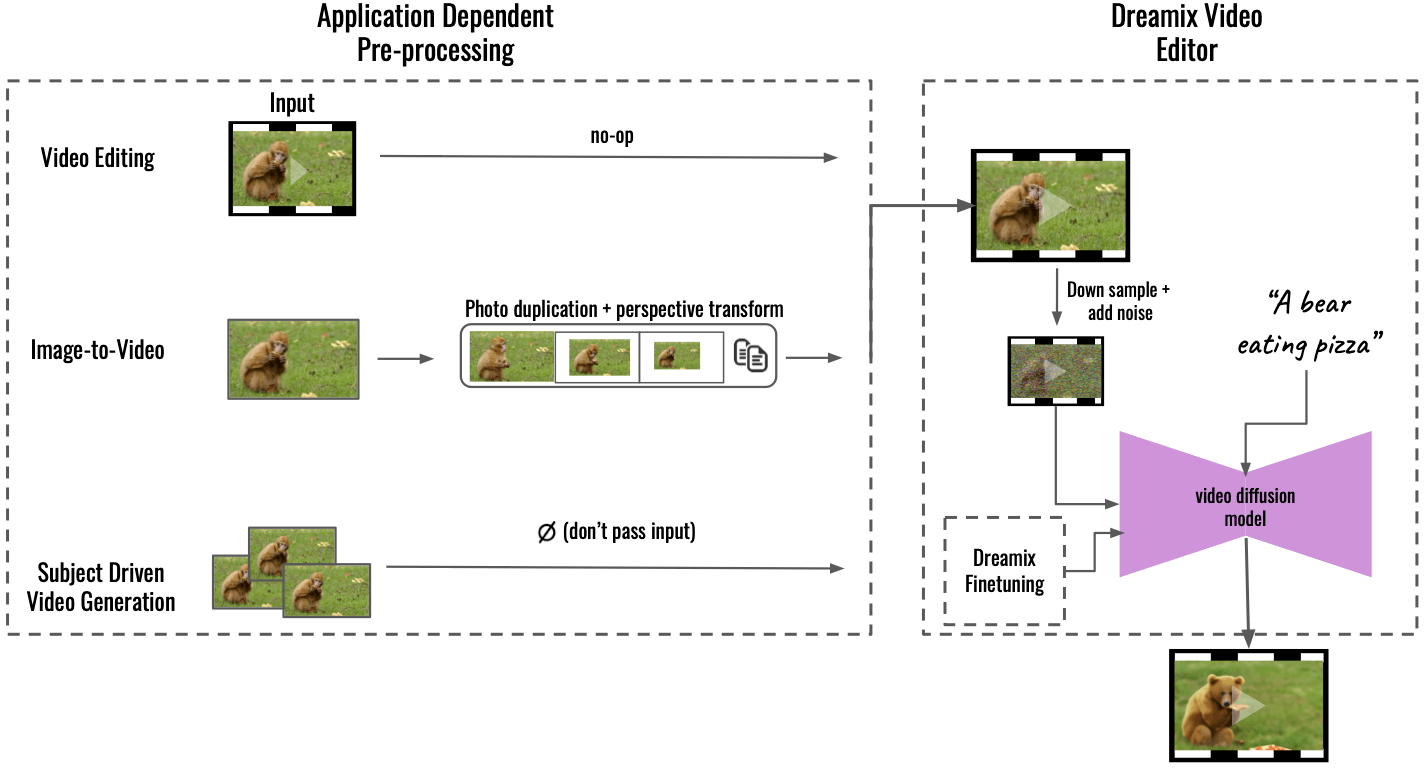
Method Overview: Mixed Video-Image Finetuning
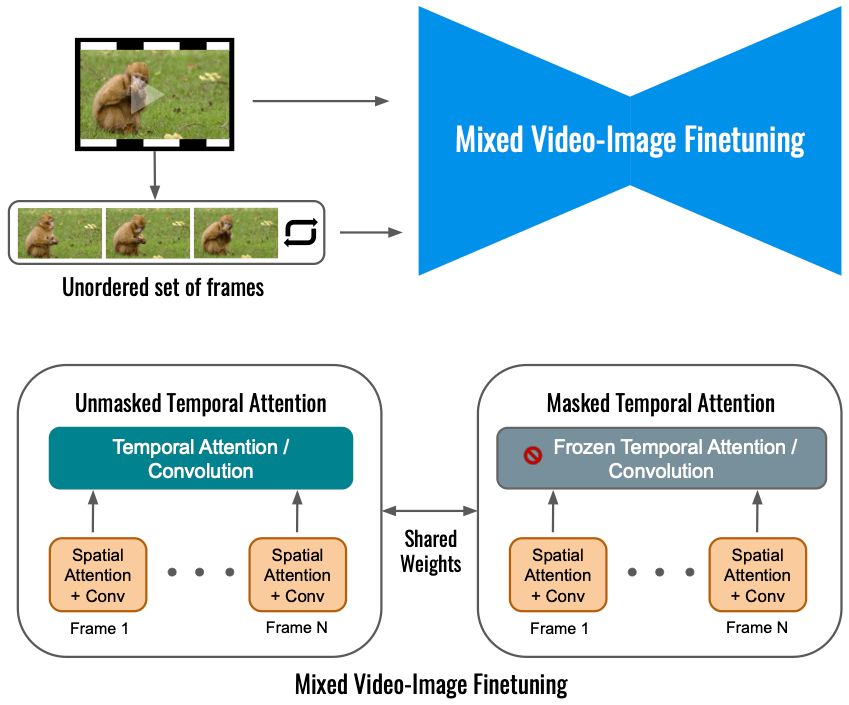
Finetuning the video diffusion model on the input video alone limits the extent of motion change. Instead, we use a mixed objective that beside the original objective (bottom left) also finetunes on the unordered set of frames. This is done by using “masked temporal attention”, preventing the temporal attention and convolution from being finetuned (bottom right). This allows adding motion to a static video.